

Managing unmanged spreadsheet data – The Setup
Does your organization conduct many operational tasks using spreadsheets? If so, you are not alone. The challenge with spreadsheets is they contain a lot of valuable information, but they tend to be passed around without any controls, quality checks, or versioning, and in so doing, can create a data management nightmare.
Consider the following example, if my general manager Greg gave a spreadsheet to Michael who gave it to me, am I sure I got the correct version of the spreadsheet? Does Greg know about the changes and additions that Michael made? Do Greg or Michael know about the data changes I made? I have had this problem come to a head in several of our data mapping projects where clients want us to map data using Excel spreadsheets.
However, we have also come into client engagements where there are several spreadsheets that need to be managed in preparation for a system implementation, such as new a new inventory management exemplified by this blog series. The question then focuses on how to clean the data in the spreadsheets to bring the information into an appropriate data management environment. Here is a simple pattern that one can use to begin taming the unmanaged spreadsheet data problem.
In this example, I am using a simple combination of MS SQL Server as the back end and MS Access as the front end, or user interface. The reason for this is twofold. If I use MS Access, the data management is limited to one person at a time on one desktop. The purpose for the management of the data is to make it available to all data consumers and for those who update the data. The use of MS SQL Server or any other server hosted database is to allow access to anyone with the credentials to log into that database. However, MS Access is a simpler tool to navigate than MS SQL Server. Other combinations can also exist in the market such as MySQL with the Excel add-in.
This is the first of six blog posts. This one is called “The Setup” because it shows an example of how a table can mimic a spreadsheet structure allowing the spreadsheet to be imported into the database.
Setting up the table structure
The first step is to look at the structure of the spreadsheet to determine what the structure of the table should be. I have created a fictional Meter spreadsheet for this example. The spreadsheet looks something like this:
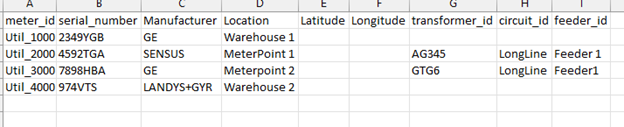
The spreadsheet was converted into a database table which mirrors the structure of the spreadsheet.

MS Access is being used as the front-end user interface here. MS Access needs to be configured to use the linked table to allow the data to move back and forth instead of working on a local copy pulled into Access.
The spreadsheet data can be added to the database and inserted into the created table which shows something like the following below:

Cracking the differences
Should a record change, a new copy of the working spreadsheet can be uploaded again, and the old and new versions of the data will be presented as shown below:

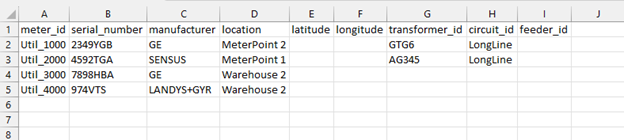
Meter id UTIL_1000 was taken from the warehouse and put into MeterPoint 2, replacing UTIL_3000 which went to Warehouse 2. In this manner the table can track differences between the different uploads from the various working spreadsheets. The use of the record identifier indicates which one was added later as noted by record id 1 vs. record id 5.
Finally, as part of data governance structure, fields can be deleted from the spreadsheet and still allow for proper ingestion, but randomly adding a new field will cause an error to be thrown as shown below:
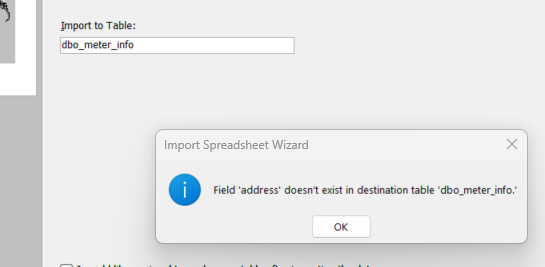
The queries can also be very powerful in terms of what data can be pulled. The latest data of the full record can be retrieved as shown below:

This can be saved as the new working spreadsheet that everyone would be making changes from. This Excel spreadsheet export can be seen below:
Find your spreadsheets
Why don’t you take a moment to catalogue all the spreadsheets used in your organization? Likely, you don’t really want to know!
As your organization grows and your data needs expand, so too should your organizations data management capabilities.
Managing the data
With the setup completed the next step is to focus on data management. An execution example is show in Part 2 of this blog series, Maturing Data Management – The Data Management.
A Better Way
This example speaks to metering, but we all know that this is only one aspect of utility operations. In the long-term “the spreadsheet – create tables” approach is not sustainable. A comprehensive inventory of an organization’s data assets is needed, sharable cross the organization. This is why Xtensible developed Affirma, our semantic modeling and metadata management solution. The Data Catalog capability within Affirma is the better way as it provides a structured and searchable catalog of the organization’s data sources, datasets, databases, tables, files, and other data-related objects.
About Affirma
 Affirma is a seamless and single point of reference for data modeling, mapping, analytics, and integration for those who are seeking to act and digitally transform through their data in support of operations and changing business needs while embracing new technologies and innovation, developed by Xtensible.
Affirma is a seamless and single point of reference for data modeling, mapping, analytics, and integration for those who are seeking to act and digitally transform through their data in support of operations and changing business needs while embracing new technologies and innovation, developed by Xtensible.
About Xtensible
Connected data and technologies provide insights adding unimaginable value for our common future. At Xtensible, we ensure that you have frictionless access to your data across your entire organization all the time. Our strategic framework defines our engagement approach, helping you do more with less. Our approach increases the trust in data used for decision making, reduces risk, and enables you to make financially sound decisions. Our services are based on a partnership mindset and deep information and data, and systems architecture knowledge and experience. We leverage industry standards to support you through your entire journey towards strategic business objectives.
Today and for the foreseeable future we will be experiencing significant shifts in both personal and corporate behavior triggered by technological advances, awareness, security, and regulatory requirements. The data journey must become more inter-connected. Want to know how?
Learn more about Xtensible Services and Affirma and how we can work together to mature data management in your organization!
Speak to a member of the Xtensible team.
ABOUT THE AUTHOR
 |
James Meyer
Consultant at XtensibleJames has been in the IT industry for more than 20 years. He has performed in roles such as solution architect, business analyst, data analyst/researcher, tester and test lead, project manager/scrum master, and helpdesk/operations support. His current focus is helping organizations better understand how to derive maximum benefit from their data through processes such as data governance, metadata management, and semantic reconciliation. A big part of this work has been in creating processes to help ensure the longevity of the investment in data management work. |
Back To Blog

